Evaluating E-Commerce Search Engines with Amazon ESCI Dataset

Evaluating E-Commerce Search Engines with Amazon's ESCI Dataset
At r2decide, we are building personalized shopping experience for e-commerce. One of its components is an intelligent search engine designed to optimize product discovery for each customer. To evaluate its performance, we benchmarked it against Algolia, Doofinder, and Shopify's built-in search using Amazon's Shopping Queries Dataset.
In this post, we detail:
- Why we used Amazon's ESCI dataset
- How we Structured the Evaluation
- How we Measured Search Quality
- How did each Search Engine Perform
- Choosing the Right Search Engine
All our evaluation setup is made available at our repository: R2-Decide/esci-batch-evaluation-dataset.
1. The Dataset
Amazon's ESCI dataset is a labeled dataset primarily designed to help evaluate search and product retrieval systems in an e‑commerce setting. The dataset provides a rich, real-world testbed for evaluating search engines. Unlike generic relevance datasets, ESCI remains an excellent resource for these reasons:
- Real Shopper Queries: All examples come from an actual e‑commerce environment, capturing authentic buyer intentions.
- Category-Specific Complexity: The dataset includes queries and products from many different categories. Some searches are super simple, while others are highly specific, making it a great resource for testing search performance across different levels of complexity.
- Varied Relevance Types: The acronym ESCI stands for: E: Exact match, S: Substitute, C: Complement, I: Irrelevant. Each product-query pair is given one of these four relevance labels. In practice, "E" means the product exactly matches the user's query (i.e., it's the perfect product for that query), while "S," "C," and "I" capture decreasing levels of relevance. This provides an efficient way to measure NDCG than a typical "relevant vs. irrelevant" approach.
For this evaluation, we focussed mainly on the Electronics category because it presents a wide range of product queries—think of the difference between searching "gaming laptop" versus "HDMI cable." Queries can range from very specific product searches (e.g., "USB Type-C charger 65W") to broader category searches (e.g., "Bluetooth speakers").
2. Evaluation Setup
2.1 Data Ingestion
We extracted Electronics category product data from ESCI, including product IDs (ASINs), titles, and metadata.
- For Algolia and Doofinder, we uploaded and indexed the product title, description, categories, and attributes for all the products.
- For Shopify, we uploaded all products to our developer store.
- For r2decide, we ingested and indexed titles, descriptions, and images. We did not include product categories and attributes, as we generate our own.
2.2 Query Execution
We extracted a set of queries from the dataset that contained Electronics product ASINs and executed them across all four search engines. Each engine retrieved the top-k results per query and we compared these results against the ground truth products from ESCI.
Using top‑k with k=5 is a common approach in e‑commerce testing since many users do not browse beyond a handful of initial results.
2.3 Query Filtering
To ensure fairness, we only included queries where the ground truth had at least k relevant products. Queries with fewer than k relevant results were not considered for evaluation.
python1ground_truth_k = [ item for item in ground_truth if len(item["product_asins"]) >= k ]
This ensures that each query has enough relevant products to meaningfully evaluate rankings.
3. Measuring Search Quality
Search performance was measured using classic information retrieval metrics: Precision@k, Recall@k, F1-score@k, NDCG@k, and MRR.
3.1 Precision@k
Measures how many of the top-k results were relevant. Higher precision means fewer irrelevant items appear in the top results.
python1precision = ( len(relevant_products & retrieved_set) / len(retrieved_products[:effective_k]) if retrieved_products else 0 )
3.2 Recall@k
Measures how many relevant products were retrieved compared to the ground truth. High recall ensures the engine retrieves most relevant products.
python1recall = ( len(relevant_products & retrieved_set) / len(relevant_products) if relevant_products else 0 )
3.3 F1-score@k
Balances Precision@k and Recall@k to provide a single measure of retrieval effectiveness. High F1-Score@k indicates that the search engine is both accurately retrieving relevant results (high precision) and capturing most of the relevant products (high recall). It is computed as the harmonic mean of Precision and Recall.
3.4 NDCG@k (Normalized Discounted Cumulative Gain)
A position-aware ranking metric that prioritizes highly relevant items appearing earlier in the results. A higher NDCG score indicates that more relevant items appear near the top.
python1def compute_dcg(relevance_scores, k): 2 dcg = sum((2**rel - 1) / math.log2(i + 1) for i, rel in enumerate(relevance_scores[:k], start=1)) 3 return dcg 4 5def compute_ndcg(ground_truth_relevance, retrieved_relevance, k): 6 dcg = compute_dcg(retrieved_relevance, k) 7 idcg = compute_dcg(sorted(ground_truth_relevance, reverse=True), k) 8 return dcg / idcg if idcg > 0 else 0
To be able to apply NDCG (which rewards highly relevant items appearing earlier) evaluation, we generated a numerical mapping (similar to approach followed here) while maintaining a structured evaluation framework.
python1relevance_mapping = { 2 "E": 3, # Exact match 3 "S": 2, # Substitute 4 "C": 1, # Complement 5 "I": 0, # Irrelevant 6}
Additionally, if a retrieved product was not found in the ground truth, we defaulted it to Irrelevant (score = 0), marking it irrelevant.
3.5 Mean Reciprocal Rank (MRR)
MRR focuses on how early the first relevant item appears in the search results. Higher MRR means users find relevant products faster.
python1rr = 0 2for rank, product in enumerate(retrieved_products, start=1): 3 if product in relevant_products: 4 rr = 1 / rank 5 break
4. Results
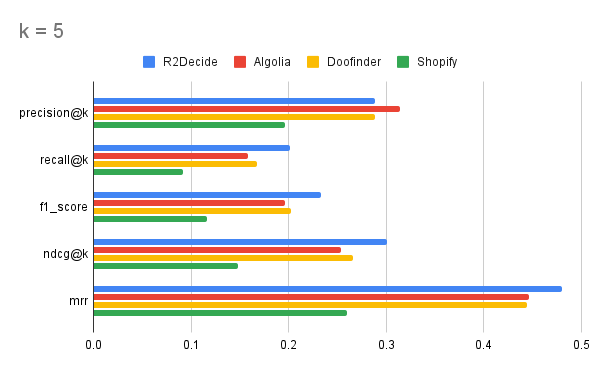
| Product | Precision@5 | Recall@5 | F1@5 | NDCG@5 | MRR |
|---|---|---|---|---|---|
| r2decide | 0.289 | 0.201 | 0.233 | 0.301 | 0.480 |
| Algolia | 0.314 | 0.158 | 0.196 | 0.253 | 0.446 |
| Doofinder | 0.289 | 0.167 | 0.202 | 0.266 | 0.444 |
| Shopify | 0.196 | 0.092 | 0.116 | 0.148 | 0.260 |
Additionally, we also calculated the average number of relevant products shown from the catalog for each of the queries.
| Product | Average Relevant Products Shown Per Query |
|---|---|
| r2decide | 1.44 |
| Algolia | 1.12 |
| Doofinder | 1.2 |
| Shopify | 0.66 |
The evaluation highlights strengths and trade-offs in how each search engine retrieves and ranks products.
r2decide: Best Overall Balance of Retrieval & Ranking
-
✅ Strong Recall and F1 - r2decide retrieves a broader set of relevant products than competitors, ensuring better product discovery.
-
✅ Highest NDCG - Outperforms others in ranking relevant items higher in the results.
-
✅ Best MRR - Ensures users find relevant products earlier in the search results.
-
🔸 Competitive Precision - Slightly lower than Algolia but still strong, meaning retrieved results may sometimes include more diverse product options.
Algolia: Highest Precision, But Lower Recall
-
✅ Best Precision - Returns highly relevant products at the top of search results.
-
✅ Good NDCG and MRR - Effectively ranks relevant products, although not as high as r2decide.
-
❌ Lower Recall - Misses more relevant products compared to r2decide and Doofinder.
-
❌ Lower F1 - Struggles to balance precision and recall.
Doofinder: A Middle-Ground Performer
-
✅ Decent Precision
-
✅ Moderate Recall - Performs better than Algolia but still significantly behind r2decide.
-
❌ F1 - Indicates a weaker balance between recall and precision**.**
-
❌ Lower NDCG and MRR - Struggles to rank relevant products effectively.
Shopify: The Least Effective Search Engine in This Test
-
✅ Provides basic search functionality suitable for general queries.
-
❌ Lowest Precision - Returns more irrelevant results than competitors.
-
❌ Lowest Recall - Retrieves the fewest relevant products.
-
❌ Lowest F1 - Indicates poor balance between precision and recall.
-
❌ Lowest NDCG and MRR - Struggles to surface the best results early.
5. Choosing the Right Search Engine
- r2decide delivers the best overall performance, leading in recall, F1, NDCG, and MRR, making it the best choice for ranking relevant results while ensuring broad retrieval.
- Algolia prioritizes high relevance, meaning only the first few results are relevant, but it misses many relevant products, leading to weaker product discovery. Good for businesses who only care about the first few results being highly relevant.
- Doofinder finds a middle ground between precision and recall, making it a decent option but not the best in any single metric.
- Shopify's built-in search lags behind the others, likely optimized for simple keyword-based searches but lacks sophisticated ranking capabilities.
Why r2decide?
Let's say your store gets 1000 visitors per day, your average product value is $100, and your average conversion rate is 3%. For every 100 products r2decide shows:
| Product | Relevant Products | Revenue | Loss in Revenue | Loss Percentage |
|---|---|---|---|---|
| r2decide | 100 | $300,000 | - | - |
| Algolia | 78 | $233,607 | -$66,393 | -22% |
| Doofinder | 85 | $254,738 | -$45,262 | -15% |
| Shopify | 59 | $176,555 | -$123,445 | -41% |
Based on the average relevant products shown across the queries, for every 100 products r2decide shows, Algolia shows 78, Doofinder shows 85, and Shopify shows just 59 products. That's loss in product discovery and revenue!
As we continue refining r2decide, we're excited to push the boundaries of AI-driven search to make online shopping faster, more relevant, and more intuitive.
🚀 Follow our journey as we build the next-gen e-commerce search experience!